
Innehåll
Källa: Kran77 / Dreamstime.com
Hämtmat:
Djupt inlärningsmodeller lär datorer att tänka på egen hand, med några mycket roliga och intressanta resultat.
Djupt lärande tillämpas på fler och fler domäner och branscher. Från förarlösa bilar, till att spela Go, till att generera bildmusik, det finns nya djupa inlärningsmodeller som kommer ut varje dag. Här går vi över flera populära modeller för djupinlärning. Forskare och utvecklare tar dessa modeller och modifierar dem på nya och kreativa sätt. Vi hoppas att denna utställning kan inspirera dig att se vad som är möjligt. (För att lära dig om framstegen inom konstgjord intelligens, se Kommer datorer att kunna imitera den mänskliga hjärnan?)
Neural stil
Du kan inte förbättra dina programmeringsfärdigheter när ingen bryr sig om mjukvarukvalitet.
Neural Storyteller

Neural Storyteller är en modell som, när den ges en bild, kan generera en romantisk berättelse om bilden. Det är en rolig leksak och ändå kan du föreställa dig framtiden och se i vilken riktning alla dessa konstgjorda intelligensmodeller rör sig.

Ovanstående funktion är den "stilskiftande" operationen som gör det möjligt för modellen att överföra vanliga bildtexter till berättelsestilen från romaner. Stilskiftning inspirerades av "En neurologisk algoritm för konstnärlig stil."
Data
Det finns två huvudkällor för data som används i den här modellen. MSCOCO är ett dataset från Microsoft som innehåller cirka 300 000 bilder, där varje bild innehåller fem bildtexter. MSCOCO är den enda övervakade data som används, vilket innebär att det är den enda informationen där människor var tvungna att gå in och uttryckligen skriva ut bildtexter för varje bild.
En av de största begränsningarna för ett framåtriktat neuralt nätverk är att det inte har något minne. Varje förutsägelse är oberoende av tidigare beräkningar, som om det var den första och enda förutsägelse som nätverket någonsin gjort. Men för många uppgifter, till exempel att översätta en mening eller ett stycke, bör ingångarna bestå av sekventiella och konjunktrelaterade data. Till exempel skulle det vara svårt att känna till ett enda ord i en mening utan de svårigheter som de omgivande orden tillhandahåller.
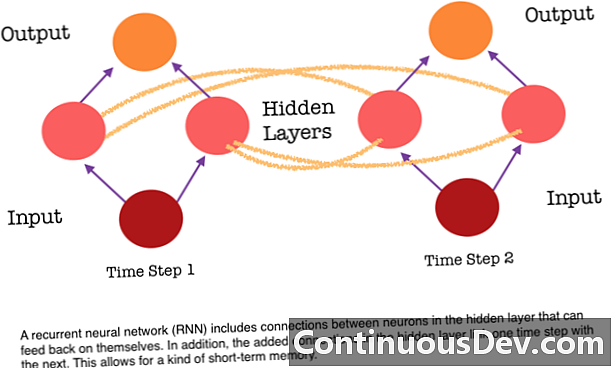
RNN: er är olika eftersom de lägger till en annan uppsättning förbindelser mellan nervcellerna. Dessa länkar gör det möjligt för aktiveringarna från neuronerna i ett dold skikt att matas tillbaka till sig själva vid nästa steg i sekvensen. Med andra ord, vid varje steg får ett doldt lager både aktivering från skiktet under det och även från föregående steg i sekvensen. Denna struktur ger i huvudsak återkommande neurala nätverk minne. Så för att upptäcka objekt kan en RNN dra nytta av sina tidigare klassificeringar av hundar för att avgöra om den aktuella bilden är en hund.
Char-RNN TED
Denna flexibla struktur i det dolda lagret gör att RNN: er kan vara mycket bra för språkmodeller på karaktärsnivå. Char RNN, ursprungligen skapad av Andrej Karpathy, är en modell som tar en fil som input och tränar ett RNN för att lära sig att förutse nästa tecken i en sekvens. RNN kan generera karaktär efter karaktär som kommer att se ut som de ursprungliga träningsdata. En demo har tränats med transkript av olika TED-samtal. Mata in ett eller flera nyckelord i modellen och det kommer att generera en passage om nyckelorden i röst / stil för en TED Talk.
Slutsats
Dessa modeller visar nya genombrott inom maskininformation som har blivit möjliga på grund av djup inlärning. Djupt lärande visar att vi kan lösa problem som vi aldrig kunde lösa tidigare, och vi har ännu inte nått den platån. Räkna med att se många fler spännande saker som förarlösa bilar under de närmaste åren som ett resultat av innovation i djup inlärning.